Convolutional Neural Networks — Part 5: Why Convolutions ?

This is the final part of my blog post series on convolutional neural networks. Here are the pre-requisite parts for this post:
- Part 1: Edge Detection
- Part 2: Padding and Strided Convolutions
- Part 3: Convolutions Over Volume and The Convolutional Layer
- Part 4: The Pooling and Fully Connected Layer
So why are convolutions so useful and when can you include them in your neural networks?
There are two main advantages of using convolutional network layers:
- Parameter sharing
- Sparsity of connections.
1. Motivation

Let’s say that you have a 32 by 32 by 3 dimensional image and let’s say that you use a 6filters that are 5 by 5. And so, we have a 28 by 28 by 6 dimensional output. Because 32 by 32 by 3 is 3,072, and 28 by 28 by 6is 4,704, there would be about 14 million parameters in the weight matrix of the standard neural network. And so, if you were to create a neural network with 3,072 units in one layer, and with 4,704 units in the next layer, and if you were to connect every one of these neurons, then the weight matrix, the number of parameters in a weight matrix would be 3,072 times 4,704 which is approximately 14 million. So if the input image were to be 1,000 by 1,000 image, then the weight matrix will just become invisibly large. However, if you look at the number of parameters in the convolutional layer, each filter is 5 by 5. So, each filter has 25 parameters plus a bias parameter, which means that there are 26 parameters per filter, and there are 6 filters, so, the total number of parameters = 26 times 6 = 156 parameters.
2. The Two Main Advantages of Convolutions
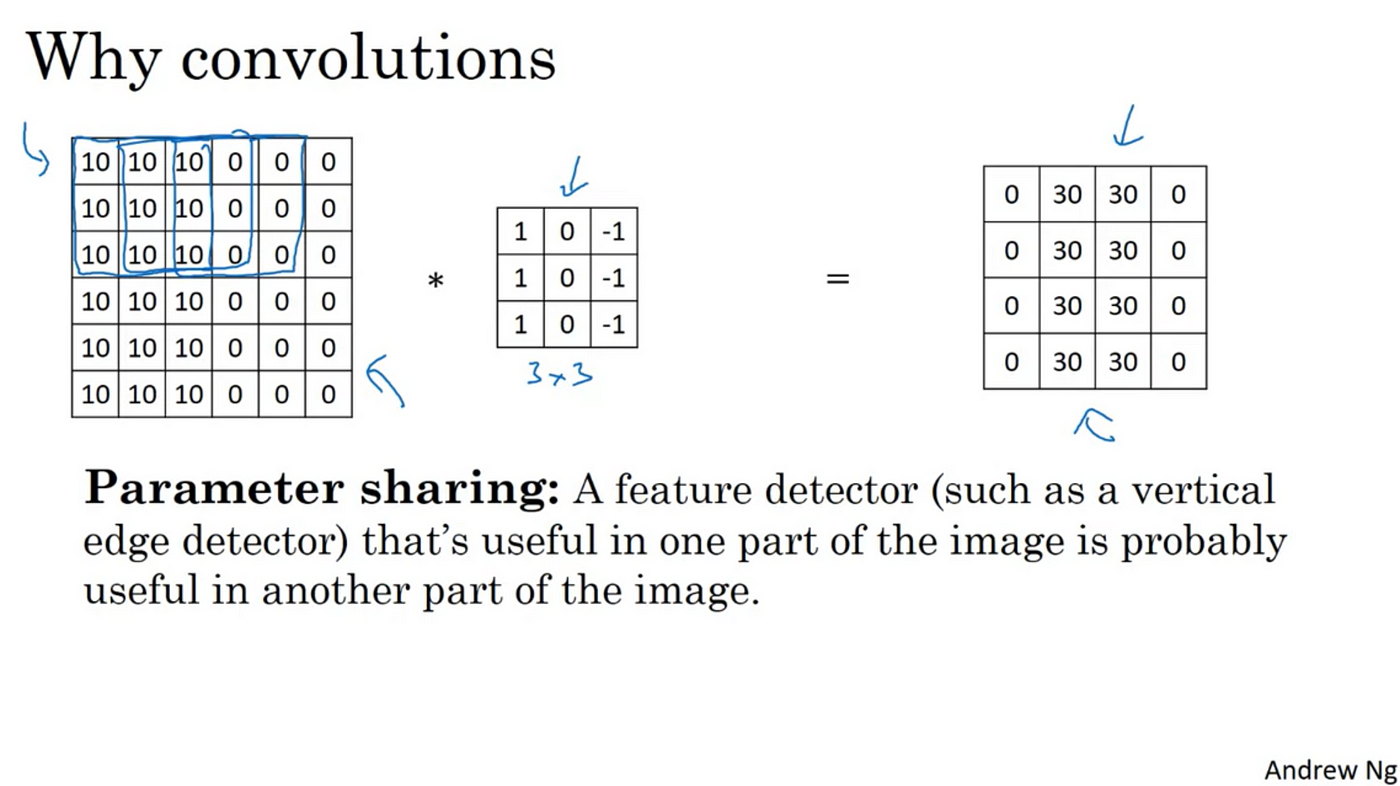
As mention before, one of the main advantages of using convolutions is parameter sharing. And parameter sharing is motivated by the observation that a feature detector such as vertical edge detector, that’s useful in one part of the image is probably useful in another part of the image. And what that means is that, if you’ve figured out say a 3 by 3 filter for detecting vertical edges, you can then apply the same 3 by 3 filter let’s say at the upper left-hand corner , and then the next position over to the right, and the next position over to the right again, and so on. And so, each of the 3 feature detectors (drawn on the image), can use the same parameters in lots of different positions in your input image in order to detect say a vertical edge or some other feature. And this is probably true for low-level features like edges, as well as the higher level features, like maybe, detecting the eye that indicates a face or a cat or something there. Being with a share, in this case, the same 9 parameters (the numbers on the 3 by 3 filter) to compute all 16 of the outputs (on the right-hand side), is one of the ways the number of parameters is reduced.

The second way that convolutional networks get away with having relatively few parameters is by having sparse connections. Here’s what that means,

if you look at the zero, this is computed via 3 by 3 convolution. And so, it depends only on this 3 by 3 inputs grid. So, it is as if the green-circled zero output unit on the right is connected only to green-shaded 9 out of these 36 input features. And in particular, the rest of the other 27 pixel values, the pixel values not shaded in green do not have any effects the green-circled zero.

As another example, the red-circled 30 at the output depends only on the 9 red shaded input features. And so, it’s as if only those 9 input features are connected to the red-circled 30 at the output, and the other pixels just don’t affect this output at all. And so, through these two mechanisms, a neural network has a lot fewer parameters which allows it to be trained with smaller training sets and is less prone to overfitting.
Sometimes you also hear about convolutional neural networks being very good at capturing translation invariance; that’s the observation that a picture of a cat shifted a couple of pixels to the right, is still pretty clearly a cat. The convolutional structure helps the neural network encode the fact that an image shifted a few pixels should result in pretty similar features and should probably be assigned the same output label. And the fact that you are applying to same filter, which goes through all the positions of the image, both in the early layers and in the late layers that helps a neural network automatically learn to be more robust or to better capture the desirable property of translation invariance. So, these are maybe a couple of the reasons why convolutions or convolutional neural networks work so well in computer vision.
Thank you for your attention. This is the final piece of my convolutional neural networks blog post series. If you have any feedback and questions, please leave a comment. Otherwise, clap and share. :)
REFERENCES:
